
Koppeling van vragenlijstgegevens en gegevens over zorgconsumptie
Na pre-analyse wordt de IMA-projectdatabase (Idata) via de TTP van de HI-fondsen naar het Data Ware House van de auteurs gestuurd, dat zal worden gebruikt om alle volledig gecodeerde gegevens te analyseren, of ze nu afkomstig zijn uit de vragenlijsten (Qdata) of van de IMA (Idata). In deze laatste fase worden de NN’s van de oorspronkelijke patiënt vervangen door projectcodes (Cproj) en worden de originele NIHDI-nummers van de arts vervangen door arts-pseudocodes (Cdoct). Enquête- en IMA-gegevens worden gekoppeld aan een geschat faalrisico van max. 2-3%.
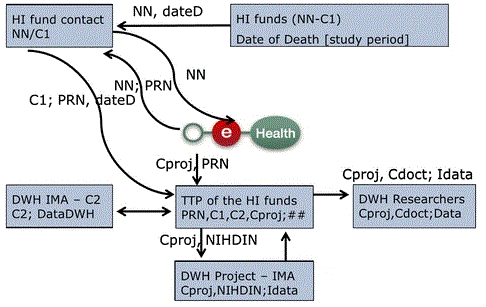
Selectie van relevante zorgconsumptiegegevens voor de retrospectieve studie
Gegevensstroom van patiënten die geen geïnformeerde toestemming hebben ondertekend (enquêtes niet beschikbaar)
Afbeelding op volledige grootte
Voor patiënten die geen geïnformeerde toestemming hebben ondertekend, zijn de inclusie en de eerste gegevensstromen verschillend en zijn de vragenlijstgegevens natuurlijk niet beschikbaar. De opname zal gebeuren in de database van de HI-fondsen zoals uitgelegd in “2.3 Studiepopulatie”.
Van deze mensen wordt het NN naar de beveiligingsfunctionarissen van de HI-fondsen gestuurd. Deze officieren sturen het NN naar eHealth. Vanaf dat moment is de gegevensstroom erg vergelijkbaar met die van patiënten met een geïnformeerde toestemming.
Data Analyse
Voor de analyse van primaire en secundaire uitkomstmaten moeten longitudinale en clusteranalyses worden gebruikt om gegevens van patiëntenpopulaties van deelnemende huisartsen te vergelijken met patiëntenpopulaties van niet-deelnemende huisartsen. Indien mogelijk zal de IMA opgenomen huisartsen matchen met controle-huisartsen op basis van leeftijdscategorie (per 5 jaar) en huisartsenkring. Als matching niet realistisch haalbaar blijkt, worden deze kenmerken van de huisartsen als onafhankelijke variabelen beschouwd.
De gegevens met betrekking tot het monitoren van de implementatie van de CPPPC en de kwaliteit van zorg en kwaliteit van leven, moeten beschrijvend worden gebruikt om de primaire en secundaire uitkomsten gerelateerd aan deelnemende huisartsen en patiënten contextualiseren. Om de patiëntenpopulaties van de huisarts te kunnen beschrijven, zullen via IMA ook gegevens beschikbaar zijn over de leeftijdscategorie van de patiënt, het geslacht, de maand van overlijden, de ziektecategorie (kanker versus niet-kanker; aanwezigheid van dementie) en sociaal-economische toestand.